Classification using Logistic regression
Classification using Logistic regression
In regression, we predict a continuous number whereas in classification, we predict the category (class) to which the data belongs. There are many classification algorithms like Logistic regression, K-Nearest Neighbors, Support Vector Machine, Naive Bayes, etc.
In this article, we will see how logistic regression works.
Introduction:
Logistic regression is a supervised learning classification algorithm used to predict the probability of a class or event. It is a binary classifier based on the Sigmoid function used to get the probabilities between 0 and 1.
Assume we want to classify if the patient can get cancer or not based on the tumor size.
Regression models won't be suitable for data with classes shown below. Here we cannot fit the regression model for classification type of data.

We have to slightly modify the linear regression equation by applying the sigmoid function so that we get the probabilities and we know that probabilities range between {0, 1}.

Upon doing the above modifications by applying the sigmoid equation, we get the sigmoid curve as shown below. The predictions will be in between 0 and 1.

Assume we have set a threshold as 0.5. For tumor size > = 0.5, there are higher chances of a patient suffering from the cancer and for tumor size < 0.5, there are lower chances of cancer.
For a new size = 0.45, we can predict the occurrence of cancer is low because the projected pink line is below the threshold value.

Program:
Import the necessary libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
We want to predict if the customer after being notified about the offers online buys a product based or not. Let us load the dataset using pandas.
dataset = pd.read_csv(r'data.csv')
dataset.head(14)

Consider only the 'Age' and 'Salary' features and exclude 'ID' and 'Gender' as they are not useful in predicting if the customer will purchase the product or not.
X = dataset.iloc[:, [2, 3]].values # all rows of 2nd & 3rd columns
y = dataset.iloc[:, 4].values # all rows of 4th column
Let us split the data into four parts X_train, X_test, y_train and y_test.
X_train and y_train: used for training model
X_test: used for predicting y_pred
y_test: used for comparing with y_pred to check performance
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
Perform feature scaling because age values range from {20, 70} and salary ranges from {10000, 200000}. One feature should not dominate the other. That is why it is necessary to scale features within the same range.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Let us create our logistic regression model.
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)
Predict the predictions of X_test and store it in y_pred.
y_pred = classifier.predict(X_test)
Find the performance of the model that we created. Here 'accuracy' metrics is being used.
from sklearn.metrics import accuracy_score
score =100*accuracy_score(y_test,y_pred) # here 89%
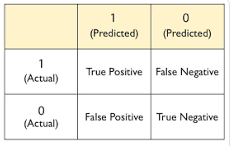
We can also print the confusion matrix which gives the summary of correct and incorrect predictions.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
[[65 3]
[ 8 24]]
According the the confusion matrix, we can draw following conclusions:
Here we have 100 instances belonging to the test data.
(i) 65 instances are predicted as '1' which is true as actual (true positive)
(ii) 3 instances are predicted as '0' even though they are '1'(false negative)
(iii) 8 instances are predicted as '1' even though they are '0' (false positive)
(iv) 24 instances are predicted as '0' which is true as actual (true negative)
So out of 100 instances, 65 + 24 = 89 are predicted correctly!!















Comments